kaggle에서 PCB 데이터 세트를 가져와 불량 클래스를 감지하는 예제를 살펴보았습니다.
사용된 실행 환경은 Annaconda Navigator와 병렬로 Jupyter 노트북과 Google의 Colab(GPU) 환경이었습니다.
https://www.kaggle.com/datasets/akhatova/pcb-defects
PCB 결함
6가지 종류의 결함이 있는 1386개의 이미지가 포함된 PCB 데이터 세트
www.kaggle.com
데이터는 kaggle에서 얻을 수 있으며 참조된 예는 다음과 같습니다.
https://www.youtube.com/watch?v=LB9SklRNDUA
비디오와 알려지지 않은 방법은 ChatGPT를 통해 연구되었습니다.
비디오의 Github 레퍼토리
https://github.com/MBDNotes/YOLOv5_PCB_Defects_Detection
GitHub – MBDNotes/YOLOv5_PCB_Defects_Detection
GitHub에서 계정을 생성하여 MBDNotes/YOLOv5_PCB_Defects_Detection 개발에 기여하십시오.
github.com
데이터 다운로드, 욜로 주석 생성
먼저 Keggle에서 데이터를 다운로드합니다.
다운로드한 데이터를 확인해보면 6가지 종류의 불량이 있음을 알 수 있습니다.
해당 데이터는 xml 파일에 주석을 달지만 yolo 모델은 텍스트 형식의 파일이 필요하므로 변환이 필요합니다.
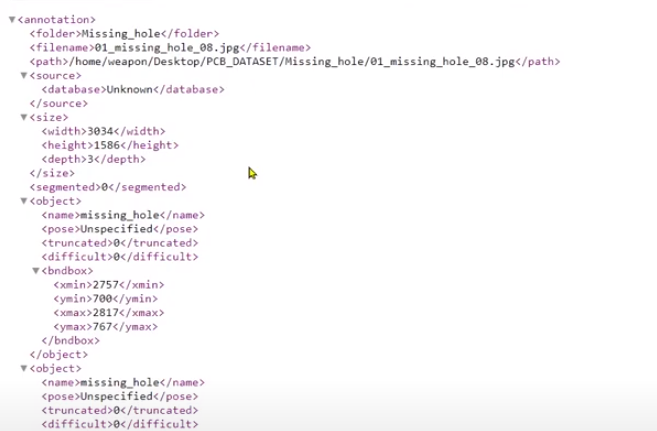
XmlToTxt github 소스를 사용하여 xml을 txt로 변환
https://github.com/Isabek/XmlToTxt
GitHub – isabek/XmlToTxt: ImageNet 파일 xml 형식을 Darknet 텍스트 형식으로
ImageNet 파일 xml 형식을 Darknet 텍스트 형식으로. GitHub에서 계정을 생성하여 isabek/XmlToTxt 개발에 기여하십시오.
github.com
GitHub를 로컬 디렉터리에 복제하고 해당 디렉터리에 요구 사항을 설치해야 합니다.
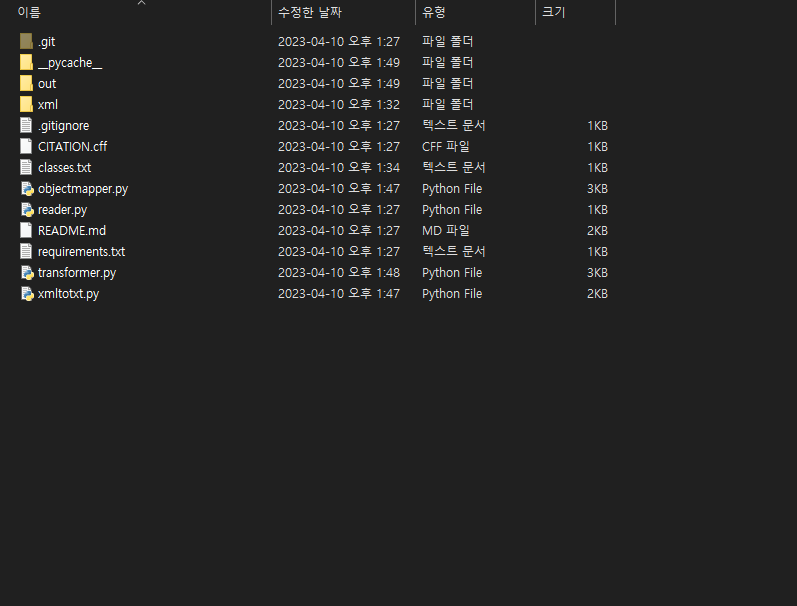
명령: python -m pip install -r requirements.txt
(이 때 오류가 발생한다면 Python이나 pip가 설치되어 있지 않은 경우이니 구글링을 해서 필요한 것들을 먼저 설치해야 합니다)
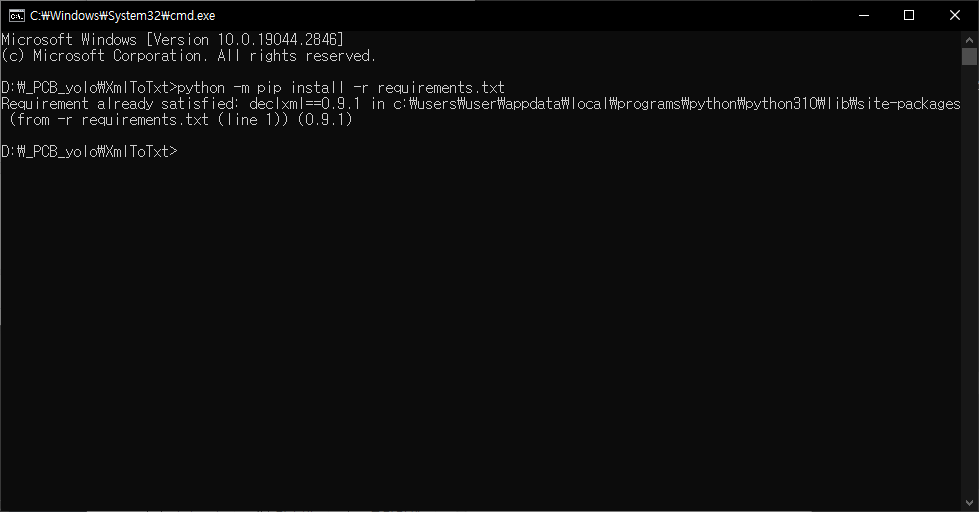
이후 앞서 다운로드한 Keggle 데이터 폴더 중 Annotations에 있는 xml 파일을 모두 복사하여 XmlToTxt의 xml 폴더에 붙여넣기(XmlToTxt의 xml 폴더에 있는 원본 예제 파일은 삭제)
탐지할 6개의 불량 클래스를 지정해야 하므로 XmlToTxt에서 classes.txt 파일을 수정합니다.
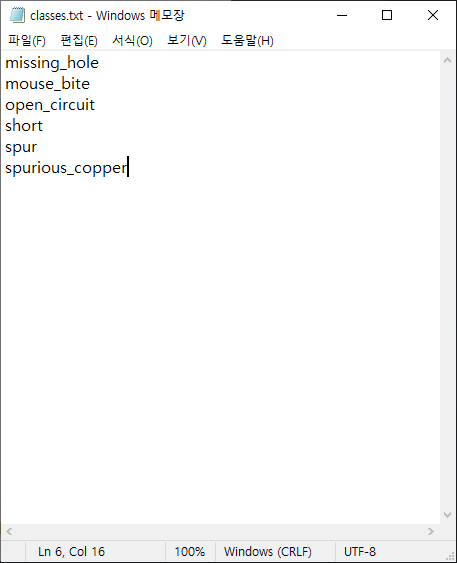
적어둔 클래스는 이전에 다운로드한 Data Annotations에서 xml 파일을 열 때 개체 중 이름으로 지정됩니다.

지금까지 파일을 준비하고 Jupyter 노트북으로 xml -> txt로 변환하는 소스를 실행해 보겠습니다. 소스에 경로를 입력할 때 슬래시를 주의하십시오.
import os
os.chidir("D:/_PCB_yolo/XmlToTxt")
!python xmltotxt.py -c classes.txt -xml xml -out out완료되면 해당 경로의 out 폴더에 텍스트 파일이 생성되는 것을 확인할 수 있습니다.
yolo 모델에서 사용하려면 모든 텍스트 주석을 복사하여 Keggle 데이터 파일 경로의 Annotations에 붙여넣습니다(이 때 기존 xml 파일은 모두 제거됨).
이 시점에서 Keggle 데이터 파일 경로에는 이미지와 댓글이 준비되어 있습니다.
모델 학습을 위한 데이터 분리
먼저 데이터 처리가 용이하도록 데이터를 분리하여 준비합니다.
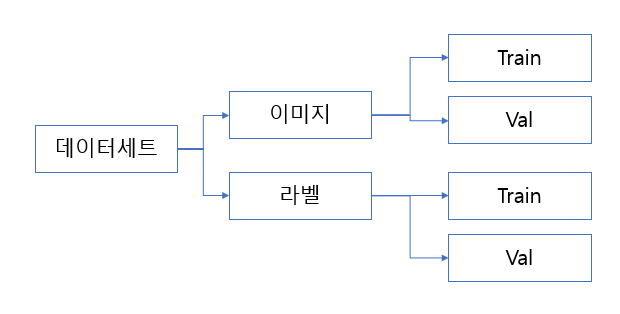
데이터를 나눌 때 학습 80:검증 20의 비율로 나누어서 진행합니다.
데이터를 분할하기 위해 미리 준비한 주석과 이미지 파일을 모두 하나의 경로에 넣습니다.
(데이터 파일에서 이미지 경로의 모든 항목을 복사하여 주석으로 붙여넣기)
그러면 Jupyter 노트북을 통해 불량 클래스별로 데이터를 나누어 저장하는 소스가 실행된다.
import os
from random import choice
import shutil
def to_v5_directories(images_train_path,images_val_path,labels_train_path,labels_val_path, dataset_source):
imgs =()
xmls =()
trainPath = images_train_path
valPath = images_val_path
crsPath = dataset_source
train_ratio = 0.8
val_ratio = 0.2
totalImgCount = len(os.listdir(crsPath))/2
for (dirname, dirs, files) in os.walk(crsPath):
for filename in files:
if filename.endswith('.txt'):
xmls.append(filename)
else:
imgs.append(filename)
countForTrain = int(len(imgs)*train_ratio)
countForVal = int(len(imgs)*val_ratio)
trainimagePath = images_train_path
trainlabelPath = labels_train_path
valimagePath = images_val_path
vallabelPath = labels_val_path
for x in range(countForTrain):
fileJpg = choice(imgs)
fileXml = fileJpg(:-4) +'.txt'
shutil.copy(os.path.join(crsPath, fileJpg), os.path.join(trainimagePath, fileJpg))
shutil.copy(os.path.join(crsPath, fileXml), os.path.join(trainlabelPath, fileXml))
imgs.remove(fileJpg)
xmls.remove(fileXml)
for x in range(countForVal):
fileJpg = choice(imgs)
fileXml = fileJpg(:-4) +'.txt'
shutil.copy(os.path.join(crsPath, fileJpg), os.path.join(valimagePath, fileJpg))
shutil.copy(os.path.join(crsPath, fileXml), os.path.join(vallabelPath, fileXml))
imgs.remove(fileJpg)
xmls.remove(fileXml)
print("Training images are : ",countForTrain)
print("Validation images are : ",countForVal)
# shutil.move(crsPath, valPath)위의 소스와 같은 함수 형태로 작성하고 os 디렉토리를 데이터 경로의 상위 경로로 지정합니다.
os.chdir("D:/_PCB_yolo")
os.getcwd()그런 다음 각 불량 클래스에 대해 데이터가 배포됩니다. 하나씩 댓글 달고 풀면서 총 6회 실행 (백슬래시가 아닌 슬래시로 경로 지정)
to_v5_directories("dataset-pcb/images/train","dataset-pcb/images/val","dataset-pcb/labels/train","dataset-pcb/labels/val", "Annotations/Missing_hole")
#to_v5_directories("dataset-pcb/images/train","dataset-pcb/images/val","dataset-pcb/labels/train","dataset-pcb/labels/val", "Annotations/Mouse_bite"
#to_v5_directories("dataset-pcb/images/train","dataset-pcb/images/val","dataset-pcb/labels/train","dataset-pcb/labels/val", "Annotations/Open_circuit")
#to_v5_directories("dataset-pcb/images/train","dataset-pcb/images/val","dataset-pcb/labels/train","dataset-pcb/labels/val", "Annotations/Short")#to_v5_directories("dataset-pcb/images/train","dataset-pcb/images/val","dataset-pcb/labels/train","dataset-pcb/labels/val", "Annotations/Open_circuit")
#to_v5_directories("dataset-pcb/images/train","dataset-pcb/images/val","dataset-pcb/labels/train","dataset-pcb/labels/val", "Annotations/Short")#to_v5_directories("dataset-pcb/images/train","dataset-pcb/images/val","dataset-pcb/labels/train","dataset-pcb/labels/val", "Annotations/Spur")
#to_v5_directories("dataset-pcb/images/train","dataset-pcb/images/val","dataset-pcb/labels/train","dataset-pcb/labels/val", "Annotations/Short")#to_v5_directories("dataset-pcb/images/train","dataset-pcb/images/val","dataset-pcb/labels/train","dataset-pcb/labels/val", "Annotations/Spurious_copper")

학습데이터가 92개 중 23개의 검증데이터로 분리되어 있음을 알 수 있다. (클래스별)
모델 학습 진행
여기까지 데이터를 준비하고 최종적으로 준비한 데이터 폴더인 dataset-pcb를 zip 파일로 압축하여 구글 드라이브에 업로드한 후 해당 데이터를 구글 colab에 마운트하여 모델 학습을 진행하였다.
Google colab은 편집> 노트 설정에서 하드웨어 가속기를 GPU 표준으로 설정했습니다.
모델 학습이 끝나면 best.pt 파일이 나오는데 이것만 받고 실행시간을 금방 끊었습니다(1일 무료용량은 고정!)
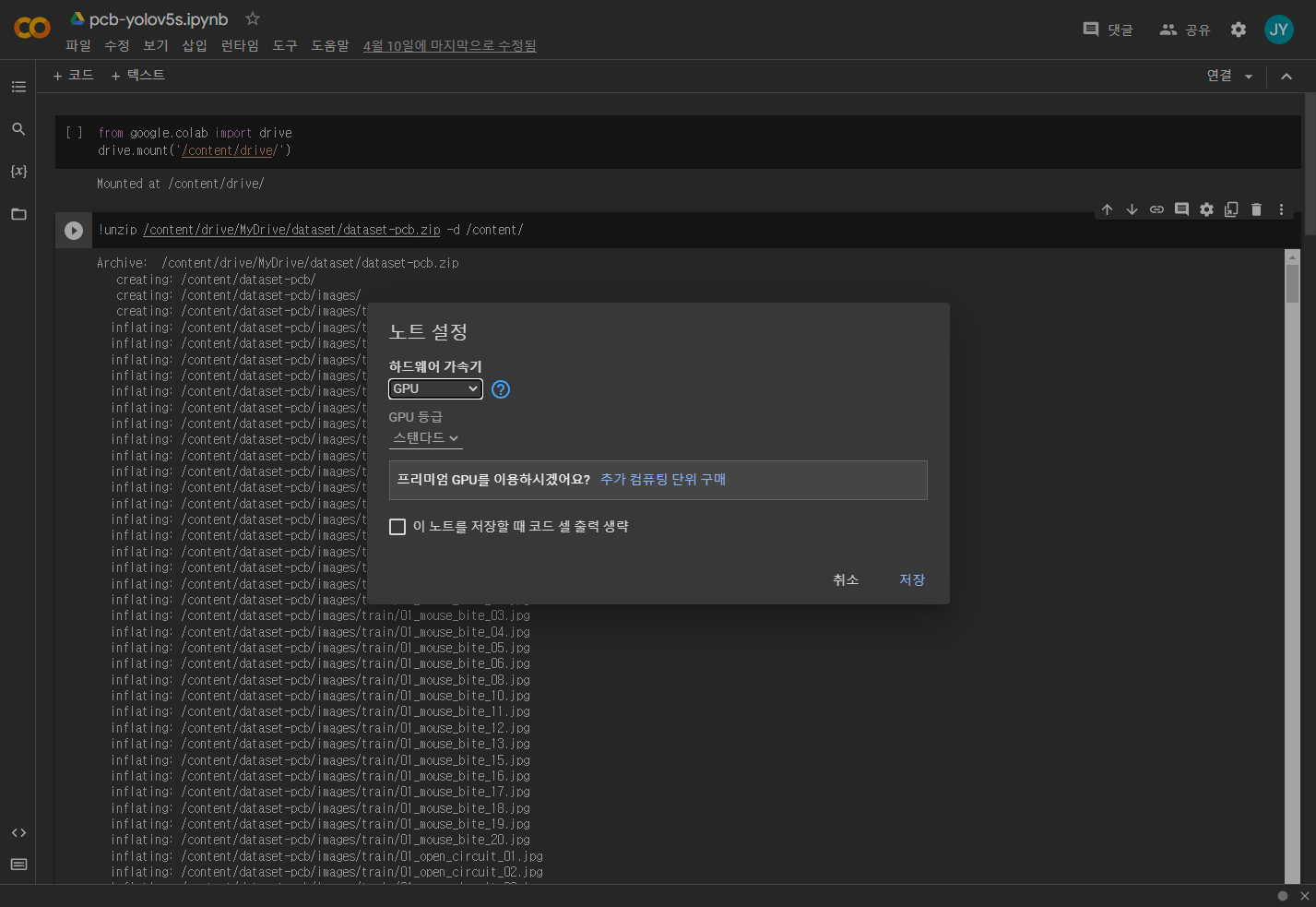
먼저 소스코드를 통해 구글 드라이브에 데이터를 마운트하여 불러옵니다.
from google.colab import drive
drive.mount('/content/drive/')완료되면 zip 파일이므로 unzip 명령을 입력하십시오.
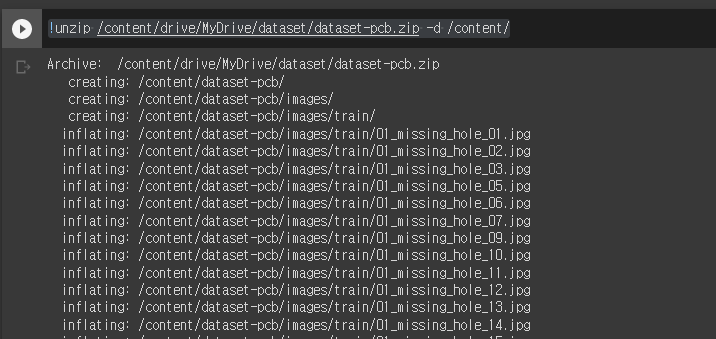
!unzip /content/drive/MyDrive/dataset/dataset-pcb.zip -d /content/
이제 사용할 yolov5 모델의 래퍼를 복제해야 합니다.
이때 경로가 최상위 수준인지 먼저 확인합니다.
import os
os.getcwd()/콘텐츠
잘 나오면 Git을 통해 yolov5 모델을 복제할 수 있습니다.
!git clone https://github.com/ultralytics/yolov5.git복제가 완료되면 해당 경로로 이동
%cd yolov5필수 구성 요소 설치
!pip install -r requirements.txt성공하면 데이터세트의 위치를 지정하고 dataset.yaml 파일을 생성해야 합니다.
dataset.yaml 파일은 메모장으로 방금 생성되었습니다.
: 옆에 공백이 있어야 정상적으로 동작합니다.
train: ../dataset-pcb/images/train
val: ../dataset-pcb/images/val
nc: 6
names: ('missing_hole','mouse_bite','open_circuit','short','spur','spurious_copper')

이전 colab에서 yaml 파일을 복사하여 yolov5 경로에 붙여넣습니다.
이제 명령을 통해 모델 학습을 진행합니다.
정확성을 위해 epoch의 수는 300, 모델 크기는 s이고 결과는 pcb_list라는 폴더에 저장되었습니다.
!python train.py --img 416 --batch 16 --epochs 300 --data dataset.yaml --weights yolov5s.pt --cache --name pcb_list모델 학습이 완료되면 yolov5 > run > train > pcb_list를 확인합니다.
각 성과지표(confusion matrix, f1 score, P curve, R curve 등) png를 확인할 수 있습니다.
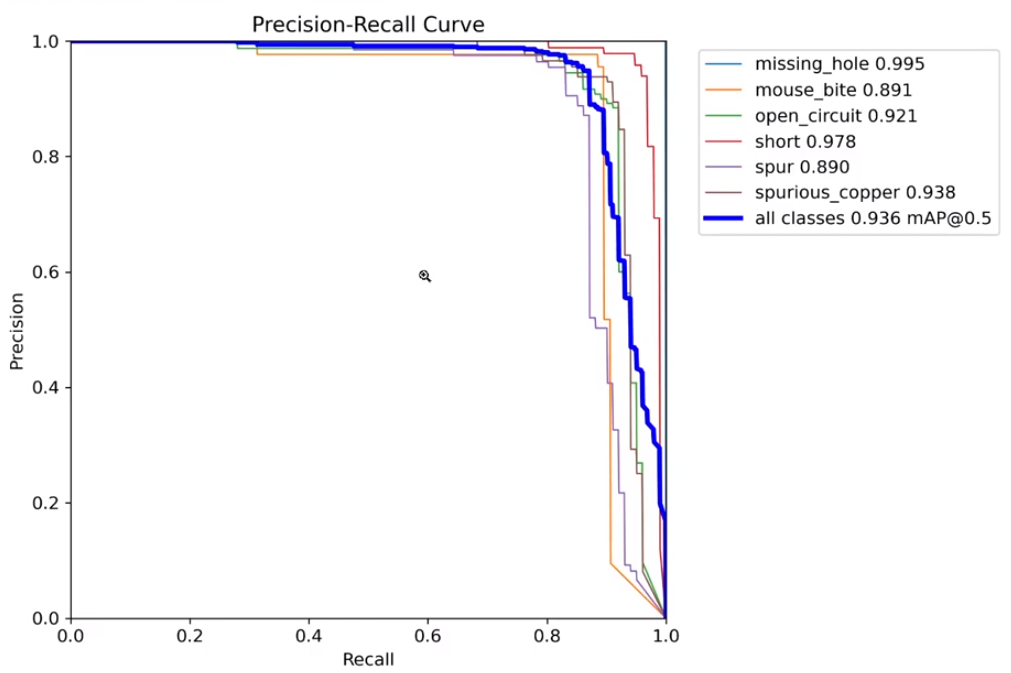
yolov5 > runs > train > pcb_list > weights 경로를 확인하면 best.pt가 생성된 것을 확인할 수 있습니다.
확인 후 확인
!python val.py --weights runs/train/pcb_list/weights/best.pt --data dataset.yaml
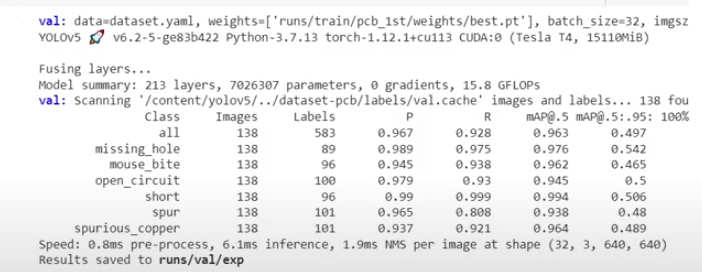
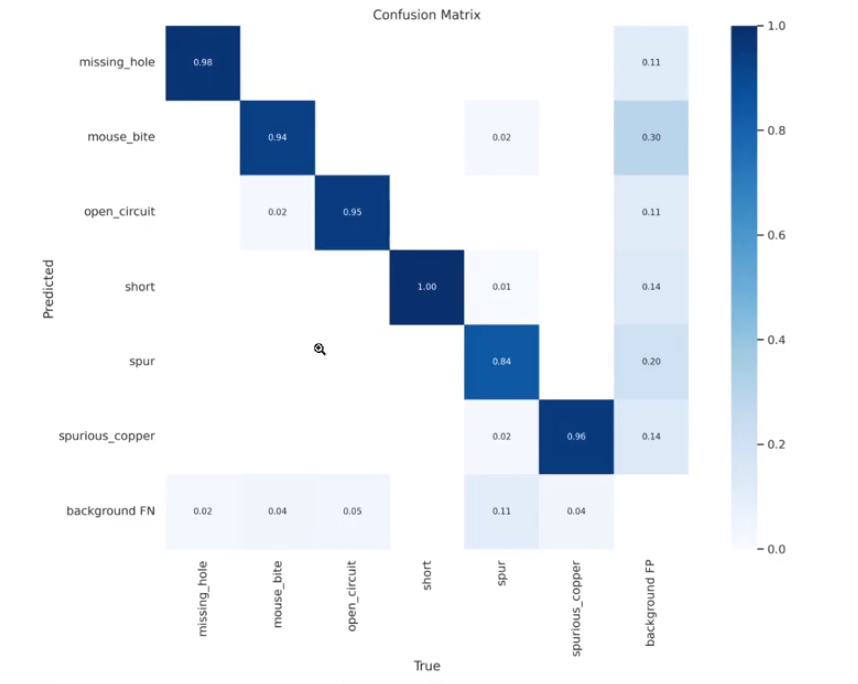
best.pt 파일만 있으면 다음부터 학습하지 않고 분류 검출을 할 수 있다.
테스트할 이미지를 colab에 넣을 폴더 경로를 test로 만들고 08.JPG로 분류했습니다.
–conf 0.5는 0.5 미만의 혼동 성능을 감지하지 않음을 의미합니다.
!python detect.py --source ../test/08.JPG --weights runs/train/pcb_list/weights/best.pt --conf 0.5성공하면 저장 경로가 나타납니다.
run/detect/exp 경로에 저장되어 있는 것으로 나왔고, 이미지 파일을 확인해보니 빠진 구멍이 감지된 것을 확인할 수 있었습니다.
